前言
这篇文章主要是痛定思痛 AI 产品如何能够更好的真正上生产。基于 AI Agent (理想中结合LLM和自主完成复杂任务)打造 LLM 应用是现在炙手可热的技术潮流,之前Case Analysis AI Agent 也打造了一个案件分析的智能体。这个智能体虽然会判断选择哪些方向进行案件调查,但是因为核心只从三个方向判断索赔案件的欺诈风险: 投保人的健康、财务和投保行为,被认为没有充分利用AI Agent的推理能力,只是一个 SOP(Standard Operating Procedure,标准作业程序)的汇总总结。一般认为,比如 Athropic 在 building-effective-agents 中的说法,这种做法因为更接近预定代码路径编排LLM 和工具,其实是工作流(Workflows)而不是 Agents。所以后面我在赔付率异动分析中探索了LLM 根据领域专家知识决定分析方向的能力,但是效果很差!事情是这样的… 首先声明,受限于企业内部安全政策,demo 阶段使用过 GPT-4o,综合效果确实好于Qwen系列。不过后续正式开发没有测试 Claude 和 OpenAI 的模型,主要使用自部署的 Qwen-72b-Instruct 和 Qwen-14b-Instruct。

业务背景
企业特定领域 AI Agent 应用按行为特征可以划分为五个类型:
| 场景类型 | 基本实现技术 | 挑战 | 场景举例(保险风控领域) |
|---|---|---|---|
| 事实提取型 | 查询、LLM 理解 | 术语复杂、歧义性强、信息冗余、LLM 幻觉 | 1. 最近一月大盘赔付率上涨多少? 2. 本季度高风险客户的续保率是多少? |
| 推理分析型 | 查询、LLM 推理 | 清晰的专家知识注入、效果不稳定 | 1. 分析近期赔付率上涨的原因 2. 分析案均赔款为什么上升 |
| 流程推进性 | LLM 理解、CRUD | 流程复杂、语言表达准确性、用户交互体验 | 1. 指导完成策略需求的细项确认 2. 端到端部署策略上线 |
| 计算处理型 | 数学运算、数据处理 | 数据准确性、算法效率、异常值处理 | 1. 计算客户群体的风险系数分布 2. 预测各营销渠道因素的贡献度 |
| 综合诊断型 | 以上 | 问题复杂度高、多维度信息融合、解释性 | 1. 分析为什么同业公司的产品策略 2. 评估大额理赔案件的核赔欺诈风险 |
我做的保险产品的赔付率(保费/赔款的比率)异动的分析&归因一开始是希望至少做成推理分析的场景类型。整个流程可以简单理解为 先计划再执行最后总结,即planning - executing -expressing。
完整理解可以参考下面的流程架构图 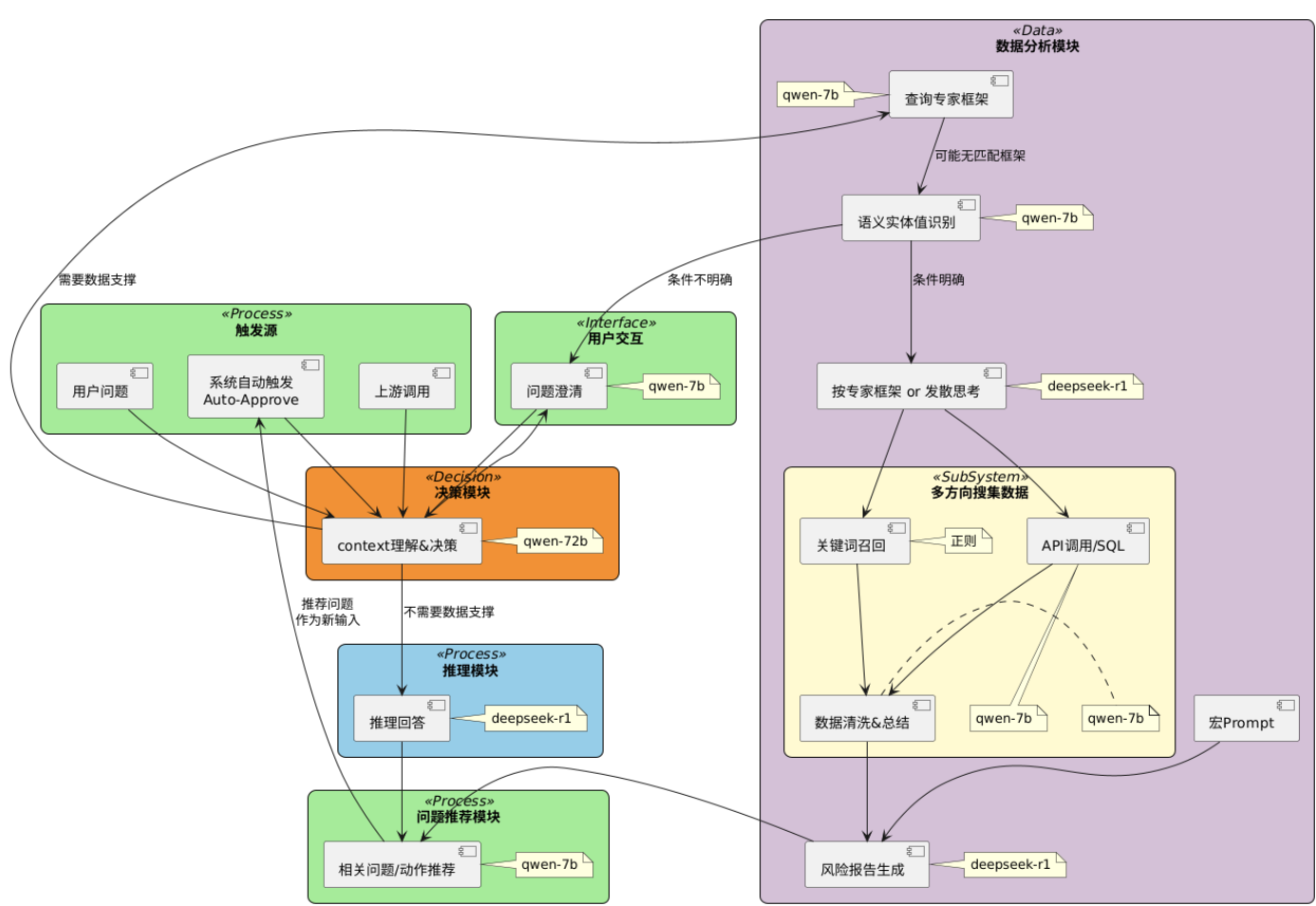
赔付率异动分析
Planning
比如赔付率分析主要从四个方面可以分析赔付率上涨/下降:
1. 宏观环境的变化
2. 精算假设的变化
3. 风控策略的变化
4. 运营策略(比如不同营销渠道流量、客群结构、产品是否升级等)的变化
不过我们和业务专家讨论下来得到了一些更细节的专家领域知识,我因为之前 workflows 的教训,所以注入了更多的专家知识 给到LLM 在 planning阶段使用,另一方面,因为展示的分析方向过多了不好看,所以限制分析方向不超过6个。这会导致LLM 有小概率不使用上面4个方向来分析赔付率异动,即使明确指令必须从4个方向思考也是一样。之后去掉注入的专家知识,不会再超出4个方向给出其他方向,但是限制分析方向不超出6个会让LLM 疑惑,甚至LLM会强行补充一个方向进去,比如“从上面4个方向综合来看,赔付率异动是什么原因导致?”因此为了效果的稳定,在理论上分析方向有很多的情况下,短期 Agents 依然会退化成workfolws。另一方面,我们后面在列表的四个方向之外,希望 LLM 思考的思路能仿照 DAG (有向无环图)呈现,所以再引入子问题。继续以上面赔付率分析原4个方向为例,我们再加入一个方向,并且prompt 中指示还有子方向,
5. 案均赔款的变化
5.1 大案案均赔款的变化
5.2 小案案均赔款的变化
最后让LLM 根据产出一个DAG(Directed Acyclic Graph,有向无环图),后端根据DAG 图执行 tool 调用,前端渲染这个DAG 图。很可惜,这更加增加了输出的不稳定,即使很明确指示LLM 不需要做任何更改原样输出prompt 中已经提供的方向,偶尔输出语义上的差别会使得后面的 executing Agent判断失误,而偶尔多生成子方向更是会直接使得前端的展示包括明显没有数据源的方向—可能会被业务认为多此一举。所以最后不仅是 workflow,希望 LLM 表现得一直符合预期,我只能直接在planning阶段放弃 LLM,而选择传统开发的方式。
Executing
executing 阶段需要将 planning 的分析方向转化为具体的tool 调用请求或者SQL,之后再由LLM 分别总结每个数据源的信息。总体上来看,AI 在结构化语句转化上的成功率挺高。但是这一阶段早期我同样注入了较多的专家知识,包括有什么样的数据指标应该怎么处理,没有数据时可以建议补充哪些信息。实践下来,发现用户对真实数据之外的信息基本不感兴趣,属于噪音,反而LLM 接收到过多专家知识后,小概率会模拟数据去计算、回答不真实的数据。目前发现缺失数据时最好的回答是什么呢?就是“xxx没有查询到相关数据。“
Expressing
expressing阶段有两个核心诉求:
- 输出事实型数据
- 输出总结类信息
对于第一个诉求,事实提取型的任务可以做一次LLM 加工后保留事实,但是做第二次 LLM 加工后,完整事实的输出概率会大大降低。所以executing 的结果可以作为事实类数据直接输出,但是不适合这个数据再进入 expressing 进行加工。对于第二个诉求,必须注意executing 是否产生了一些假设、推断类的信息,LLM 极容易忽视这些信息而当成真实结论总结输出,大大降低报告的可信度。比如当planning阶段产出的方向和查询到的数据源事实数据不完全匹配时,executing 会提示这些数据与原问题的“可能”关系,这时要么 LLM 忽视“可能” 的关系,要么Prompt 中 明确让LLM 忽视“可能”类的信息,从而在 expressing 阶段原有的事实数据被忽视。
expressing阶段完成了上诉核心诉求后,整体展示还需要受到重重审视。和市场上常见的搜索-总结类产品如 perplexity.ai 或者kimi search 等类似,AI 数据分析、归因类项目本质上是对原本有的数据做一次包装。比如原本有一个分析赔付率上涨原因的功能,AI 实际做的是在有了这个功能基础上去更好地展示原有的数据。换句话说,如果原有功能产生的数据不完整或不正确,AI 的回答则完全没有参考性,AI 在其中也没有任何价值,这时候 LLM 能按照拒绝策略输出“没有查询到相关数据”而不要因为缺少信息说废话甚至胡编乱造才是合适的。在缺少数据的时候,让 LLM 能稳定按照拒绝输出的一个方法是同样提供拒绝策略的 few-shot,否则 LLM 很容易过度模仿有数据情况下的 few-shot,从而导致错误。一开始,你可能认为 LLM 可以从原始信息中发现一些值得参考的原因,比如从提供的宏观环境、政策变化中发现一些赔付率波动的原因: 监管变严、报行一致、医疗成本上升、自然灾害变多等等。但是这些原因实际上也是老生常谈,因为每个保险产品基本都面临这样的宏观环境,所以这些知识同样会遭受到用户的抱怨,因此,在企业内部非常依赖内部原有数据的场景下,“宏观环境”这种比较通用的分析方向缺少其价值,目前也会直接去除。
再次反思
产品是用来解决问题的
AI 是一个好东西,但是我依然认为AI 就是个工具,即使指望 AI 能扮演起Agent 的角色,承担Agent 应该承担的自主“责任”,AI 如果在某个场景表现不好,就应该思考要不要替换掉它。
prompt 二义性
你写的 prompt 可能很丰富,包含很多技巧和最佳实践。但是越是丰富的 prompt 越是可能存在前后不一的二义性。一般来说,二义性有这几种
二义性分类
- 语义二义性
- 同一词语在不同上下文有不同含义
- 指令的适用范围不明确
- 专业术语解释不统一
- 格式二义性
- 数据格式规范不一致
- 输出结构模板差异
- 标点符号使用不统一
- 逻辑二义性
- 条件判断标准冲突
- 优先级规则不明确
- 异常处理策略矛盾
比如 prompt中先后 提到
小数指标应该保留4位
比率类的指标应该转化为两位百分比
这就是一种二义性。再比如某个 few-shot 中你让LLM 输出 markdown 表格如下:
| xx | xx | xx |
| --- | --- | --- |
| 1 | 2 | 3 |
后面的 few-shot 中 让LLM 输出 markdown 表格如下:
|xx | xx | xx |
|:--- |:--- |:--- |
| a | b | c |
这同样是一种二义性。prompt 中的这些细小差别不一定会导致结果有问题,但是有小概率导致结果不符合预期。现在我每个prompt 大幅更改后都会扔给LLM 先批评一遍,有助于发现自己表达的问题。所以有单元测试(还不太好做,探索中)和使用版本控制管理 prompt很重要。
重视小概率表现
不能轻视 AI 任何一次对于预期回答的偏离! 通过在 prompt中打补丁,头疼医头、脚疼医脚的方式可能在你使用的时候解决了问题,但是在更大规模使用的时候会暴露原问题。
LLM 应用是很容易造成老板/产品/技术错误判断的存在,如果轻易承诺,肯定会坑了自己。如果自己做了,但是尝试的次数过少,忽视了一些小概率badcase,也会坑了自己。
总结
所谓AI Agent,我认为其终极目标是成为可以比肩原岗位员工的数字员工。但是当前的 AI Agent,端到端的做到一个垂直业务效果依然不稳定,并且前期需要大量的人力建设。时髦来说,就是不是可scaling的状态。目前 AI 的 demo 可能一周就完成了,但是要得到令人满意的产品效果一个月也完成不了。我认为AI项目的本质需要回归工程能力与优质数据结合本身,缺一不可,
这就是当前总结的一些教训。