风销一体·从零做宠物商城推荐
1. 系统概述
1.1 业务背景
蚂蚁保中,宠物险用户在购买保险时,对宠物商品也有强烈的购买需求。购买的宠物保险可抵扣部分宠物商品支出,日常的宠物保健商品也有助于降低宠物险的赔付率。因此,宠物商城推荐成为重要业务场景。
用户在购买宠物险时,风控领域会沉淀许多不同于传统电商的数据,如用户职业、常住地、会员等级、宠物信息、投保行为等。将这些风控领域特有的用户数据应用于商品推荐,使”风销一体”成为业务增长新方向。在蚂蚁的场景中,在蚂蚁的业务场景中,有很多都是垂直的小于万级别的item推荐,本系统正是针对这样的场景进行设计。
1.2 系统架构
1.2.1 分层架构
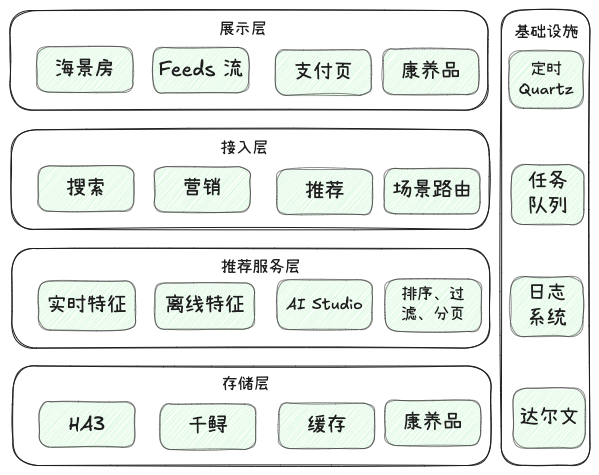
1.2.2 流程架构
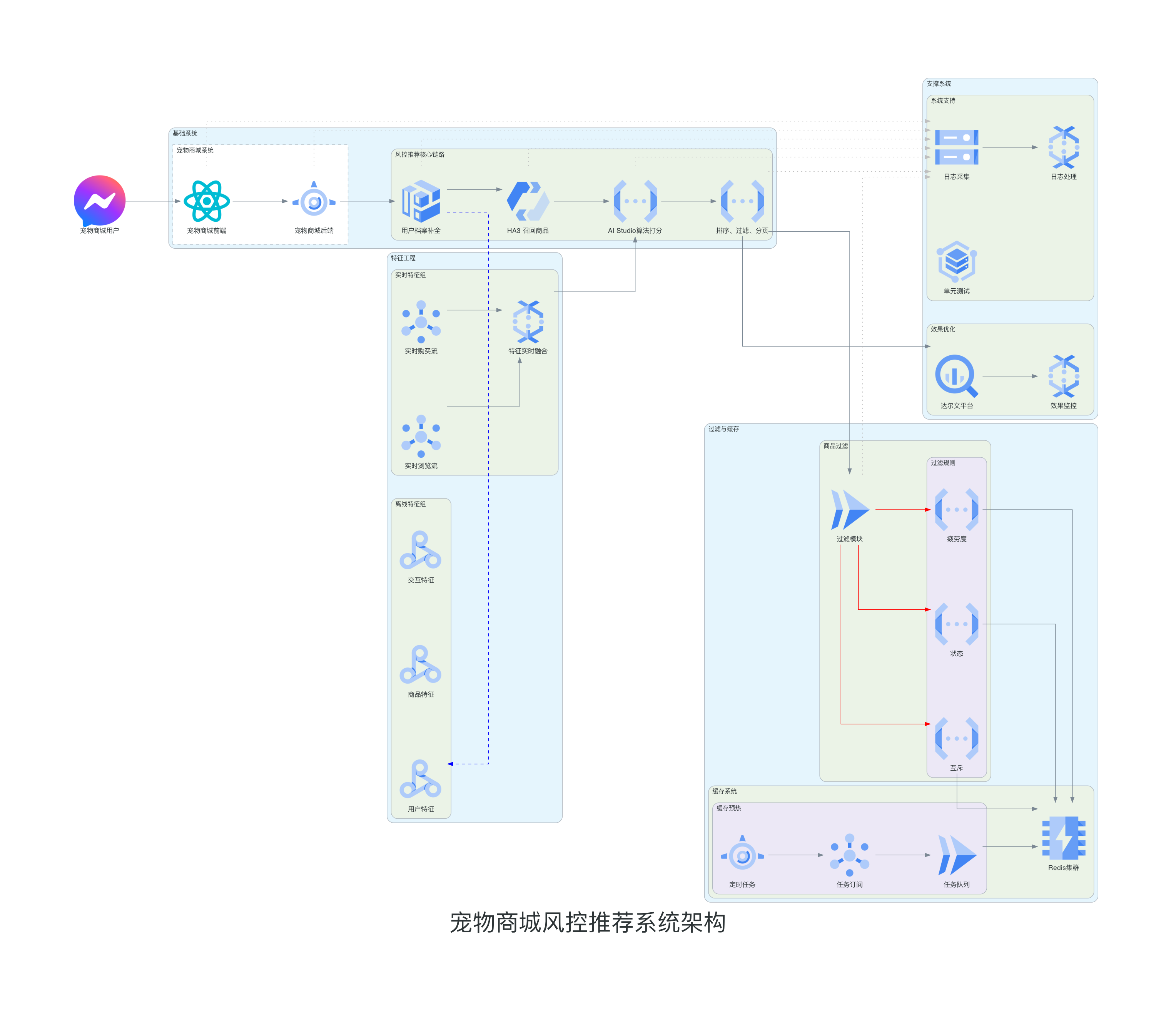
宠物后端服务从营销、搜索、风控推荐三个渠道获取商品信息,最后返回给前端展示。风控推荐核心系统首先基于用户档案信息丰富召回请求,融入风控数据并补充用户画像;然后进行商品召回获取候选集;接着构建并融合离线和实时特征;随后使用算法打分、排序和过滤;最后分页返回结果。系统设置稳定策略作为兜底,确保服务可用性。
特征工程包含离线特征和实时特征两大部分。离线特征包含三类基础特征:user特征涵盖用户的基础画像、会员信息和行为数据;item特征包含商品的基本属性、统计数据和时序特征;user2item特征记录了用户与商品间的交互行为。实时特征则包含用户实时浏览商品数据和购买商品数据,这些实时数据实时整合进特征 contenxt 用于算法消费。
缓存预热系统通过三个机制协同工作:定时任务负责按照预设的时间周期触发预热操作;任务发布与订阅机制确保预热任务能够及时分发和执行;分布式任务队列则实现了任务的均衡分配和执行状态追踪。这三个机制共同作用,实现了数据的预加载和更新。
商品过滤系统实现了三重过滤机制:疲劳度过滤通过控制商品的展示频次和时间间隔,避免重复推荐;互斥过滤通过维护互斥队列,确保相关商品不会同时展示;商品状态过滤则负责检查商品的实时状态,包括库存、上下架状态等关键信息。
效果优化系统以达尔文实验平台为核心,测试、监控与日志系统见下文详解。
1.3 领域模型设计
待完善
根据不同营销场景(可以直接查看支付宝-宠物险-买药页),推荐形式包括:
- 新人购买场景:特定商品池配合优惠策略
- 主题推荐:康养、玩具、季节性主题
- 无限 Feeds 流推荐
- 支付页相同供应商物流聚合推荐
因此系统设计需注重可读性和扩展性,通过面向对象、多态、接口组合和模版类等方式实现,而非简单的参数路由。
根据不同营销场景,推荐形式包括:
- 新人购买场景:特定商品池配合优惠策略
- 主题推荐:康养、玩具、季节性主题
- 无限 Feeds 流推荐
- 支付页相同供应商物流聚合推荐
因此系统设计需注重可读性和扩展性,通过面向对象、多态、接口组合和模版类等方式实现,而非简单的参数路由。
2. 特征工程
2.1 用户特征(User Features)
- 基础用户画像
- 基础宠物画像
- 用户保单画像
| Feature Name | English Description | 中文描述 |
|---|---|---|
| pet_nobaby_flag | Pet No Baby Flag | 宠物无幼崽标志 |
| pet_specias | Pet Species | 宠物物种 |
| pet_type_desc | Pet Type Description | 宠物类型描述 |
| pet_age | Pet Age | 宠物年龄 |
| pet_gender | Pet Gender | 宠物性别 |
| reside_city_name | Residence City Name | 居住城市名称 |
| prov_name | Province Name | 省份名称 |
| current_grade | Current Grade | 当前等级 |
| occupation | Occupation | 职业 |
| edu_level | Education Level | 教育水平 |
| is_has_marry | Marital Status | 婚姻状况 |
| user_gender | User Gender | 用户性别 |
| user_age | User Age | 用户年龄 |
…
2.2 商品特征(Item Features)
- 宠物商品基础属性
| Feature Name | English Description | 中文描述 |
|---|---|---|
| price | Price | 价格 |
| applicable_pettype | Applicable Pet Type | 适用宠物类型 |
| brand | Brand | 品牌 |
| supplier_id | Supplier ID | 供应商ID |
| category_id | Category ID | 类目ID |
…
2.3 用户-商品交互特征(UI Features)
- 浏览行为分析
- 购买行为分析
| Feature Name | English Description | 中文描述 |
|---|---|---|
| petcard_level_item_quantity[360/180/90/30]d | Pet Card Status | 不同时间窗口的宠物卡等级商品数量 |
| tblevel[1/2/3]item_quantity[360/180/90/30]d | TaoBao item Level Status | 不同等级商品在各时间窗口的数量 |
| exposure_flag_30d | Exposure Flag 30d | 30d内的曝光商品 |
| click_flag_30d | Click Flag 30d | 30d内的点击商品 |
| count_order_30d | Count Order 30d | 30d内的订单数量 |
2.4 实时特征(RT Features)
实时特征包含:
- 用户实时浏览商品
- 用户实时购买商品
实时特征通过 Flink 监听消息流更新实时表维护,在需要时与离线特征一起组装给算法模型使用。
3. 推荐算法
3.1 商品召回策略
实际召回商品依赖商品搜索接口,商品接口提供的深分页能力不超过100条,因此没有办法多路召回,只能迭代器每次取100个商品。幸好目前商品总数在600个不到,这个方案可以接受。不过目前未命中缓存的一次全量商品召回平均耗时大约500ms,因此总体的推荐性能很容易被拉高,有效的缓存策略十分必要。待会儿缓存模块再介绍。当然你说如果商品很多怎么办,不容易OOM 吗?是的,所以商品数量超过5000时,就必须要先做粗排了。即可以先从HA3 这样的搜索引擎由搜索引擎打分排序,召回适合精排的商品集合后再由精排模型打分。
3.2 打分模型
打分模型及模型参数托管在AI Studio上,在 arec 上配置,可以通过arec配置在每次打分请求时调整,这也是AB 实验的基础。因为我只有上学时候略微接触过一点深度学习算法,对于推荐算法更不熟悉,这里简单从我的理解介绍一下推荐算法的工作原理。欢迎指正错误!可以先想象我们正在培养一位优秀的宠物商品导购—即我们的推荐模型。我们的导购正需要学习如何为每一个铲屎官挑选当前最适合他们家主子的美食。
收集和整理信息(特征准备阶段)
了解铲屎官和宠物
这一步上面特征工程准备的 user 特征 & u2i特征 都会被消费。比如
- 铲屎官的年龄、性别、经济实力
- 养的是喵星人还是汪星人、年龄、品种
- 消费习惯:
- 最近一个月买了什么(短期兴趣,可能在尝试新品)
- 最近三个月买了什么(稳定喜好)
- 最近一年买了什么(长期偏好)
- 实时消费:刚刚看了什么、买了什么
了解商品
这一步上面特征工程准备的 item 特征 都会被消费。比如
- 商品贵不贵
- 商品哪个牌子
- 商品是主食、零食还是药品
- 商品为哪个阶段的宠物设计
- 是不是新品
信息处理(特征处理)
我们的导购习惯用数字表达它的推荐程度,比如0代表不推荐、1代表强烈推荐。所以特征可能会进行如下处理:
- 数值化:将非数值特征转化为数值特征,比如性别(男=1,女=0),从而让计算机可以数学运算
- 归一化:将数值特征缩放为0-1之间的数值,比如价格1000→0.1,10000→1,避免数值差距过大影响导购学习
- embedding: 将离散特征转化为向量
学习导购技巧(模型训练过程)
学习成功案例(正样本)
我们的导购需要总结出用户购买订单或者冷启动没有订单时哪些商品更受人喜欢的规律,好比它可以思考说
- “哦,上次这位铲屎官买了这款猫粮,它家猫主子应该还会喜欢”
- ”这个品牌的狗粮,经常被人回购,这个人刚来也推荐一下“
学习失败案例(负样本)
同样重要的还要总结出用户为什么不买或者说哪些商品不受人喜欢的规律,比如
- 顾客多次看了都没点击的商品,可能不够吸引人
- 顾客多次点击了也没购买的商品,可能同类商品有更好的
这其实是总结踩坑经验,不断提高导购的推荐转化率。
如何学习
如何让模型真的从特征数据中学习到正负样本的规律是推荐算法的核心。以反向传播的学习机制为例,
- 前向传播: 我们的导购看到用户和商品信息后,会基于已有的参数在它的多元神经元网络中进行计算,先得到一个预测的推荐分数
- 误差计算: 将预测分数和实际情况(用户是否购买)对比,计算预测误差(损失函数)。比如导购说这个基本上会买(推荐分数 0.9),结果没买;或者这个大概不会买(推荐分数 0.1)。
- 反向传播过程: 知道有了误差,就要知道是哪一步导致了这个误差。所以从最开始看到特征开始,逐层向后传递,计算每个参数对误差的影响,目标是找到最适合的参数使得误差最小(梯度下降)
- 参数更新: 基于计算出的梯度不断更新参数并重复这个过程,最终得到最为拟合实际情况的模型,这样也就是完成了学习
- 防止过拟合: 有时候样本太少,模型以为他学习的这些就是全部规律,从而不适合其他场景,比如他以为很少的样本里狗粮就只有这款卖出去了,那其他的狗粮都不好卖,这就是过拟合。为了防止这种情况,可以通过 Dropout 随机的神经元(好比让导购不能依赖固定的判断标准)、早停策略(好比让导购差不多学习到了就行了,防止死记硬背)等来防止过拟合
学习效果检测
学习完了之后就可以让市场检验了,市场上会看这么几个指标:
- 点击率(CTR,Click Through Rate):点击量/总访问量
- 转化率(CVR,Conversion Rate):购买量/点击量
- 用户价值(UV, User Value): GMV/User-View-Count
3.3 重排、过滤与分页
模型打的分一般指的就是 CVR 、CTR 或者综合的一个 score。在按照商品分数的高低直接推荐给上游之前,我们还需要考虑到
- 商品是否现在刚下架了?
- 这一个场景的推荐和同屏的是否有重复?
- 对于商品疲劳度运营有新动作,模型来不及学习负样本怎么办?
最后在对商品过滤、重排后分页返回推荐商品。
4. 系统工程化
4.1 缓存系统设计
由于商品召回的平均耗时达到500ms,仅依赖搜索接口无法满足性能要求。同时需要考虑商品状态实时性,避免推荐已下架商品。因此设计了以下缓存架构:
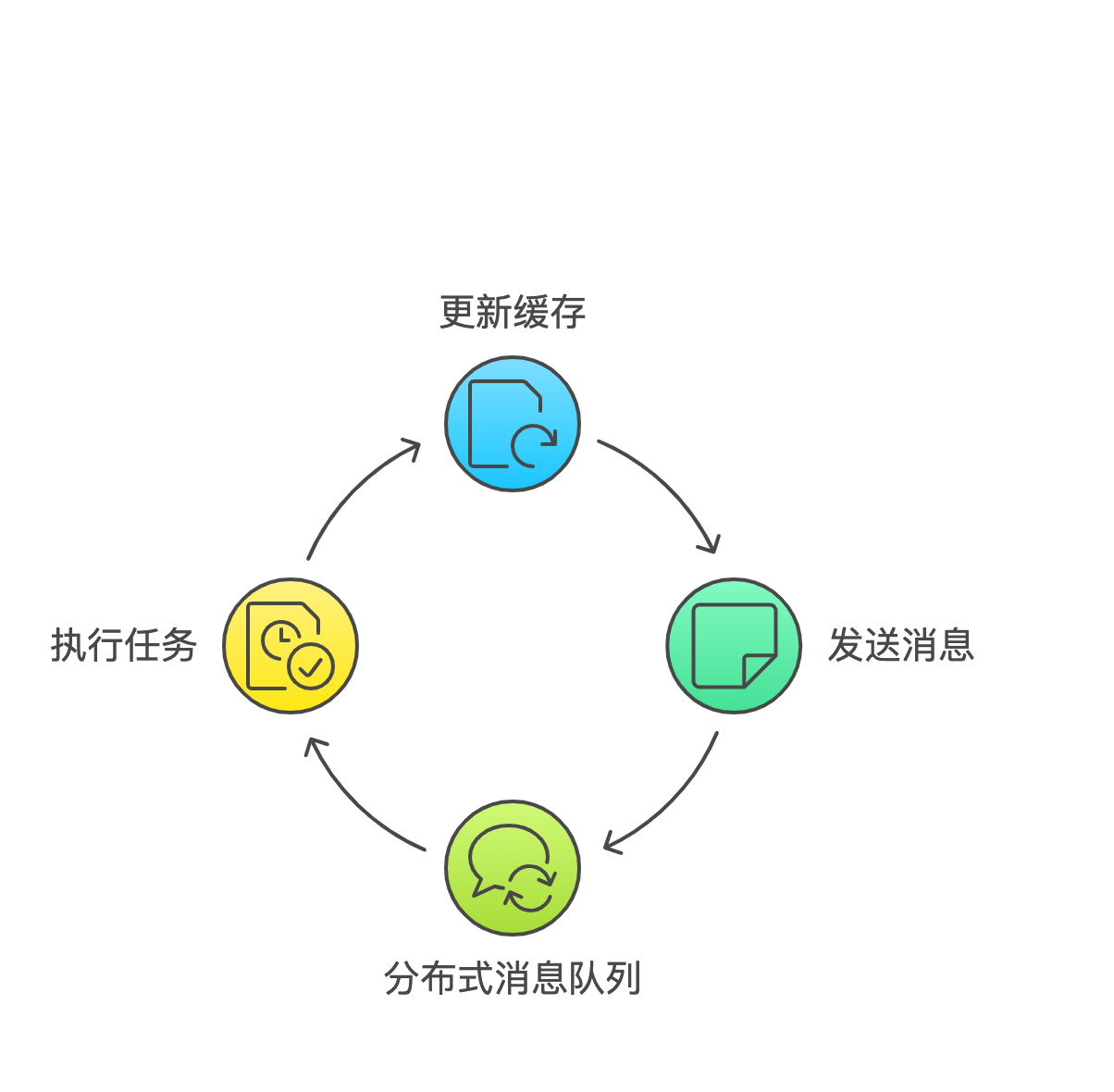
- 实时请求处理
- 接收用户请求并记录召回方法
- 检查缓存并返回结果
- 异步更新缓存以保证数据新鲜度
- 任务分发机制
- 将用户请求转化为预热任务
- 基于Redis实现任务去重
- 通过消息队列分发任务
- 预热执行
- 线程池并发处理
- 模拟用户请求更新缓存
4.2 测试框架
在推荐平台中开发的业务代码本质上是一个 嵌入到整体推荐流程中的Java bundle,所以业务开发只能写单元测试,没办法写端到端测试。单元测试不可避免地要造数据,这里我自荐一下我写的JUnit5 & Mockito 以及配合junit5-extension写参数化测试,可以更好更快地写测试。
4.3 日志系统
4.3.1 无盘化日志
在推荐平台的容器化设计场景下,一台物理机可能运行上百个容器,传统的日志落盘采集方式对物理机磁盘的竞争很大,会影响日志写入性能,间接影响应用的RT;同时每天物理机需要为各个容器准备日志的磁盘空间,造成巨大的资源冗余。因此容器中的日志实现基于推荐虚拟出一个日志盘,并直接通过用户态文件系统对接Logtail并直传到SLS。
不过这样实操中遇到一个问题,那就是实际上传到 SLS 的其实是一串String,以前落磁盘日志如果日志不规范,多少还能看 trace,现在如果不规范,仅仅一个 String 大字符串分词可能都失败,那么对于各种各样的日志场景怎么统一一下?
4.3.2 日志模型
5. AB 测试与监控
AB 测试主要仰仗达尔文,为什么不自己基于日志洗一洗,算算 GMV、UV 就好呢? 这是因为指标统计是有置信度的。监控告警只要日志做得好,配一配就好。不过要注意的是作为 toC项目,A/B 测试的指标要经常关注,也关注运营变更。
- 性能监控
- 效果监控: 监控GMV增长、监控 A/B 测试指标
- 异常监控: 监控错误增长率,监控非超时错误
5. 项目总结
本次风销一体的项目目前取得了超出预期目标的效果,事实证明将风控特征用于商品推荐是一条可行的推荐增长路径。本文主要记录下这个实践过程,缓存预热、无盘化日志模型以及单元测试可以给其他类似工程做一借鉴。推荐工程链路搭建好后,大部分的效果优化还是靠算法基于 AB 实验的模型迭代,工程重点是做好可用性和对新场景的扩展性。