



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
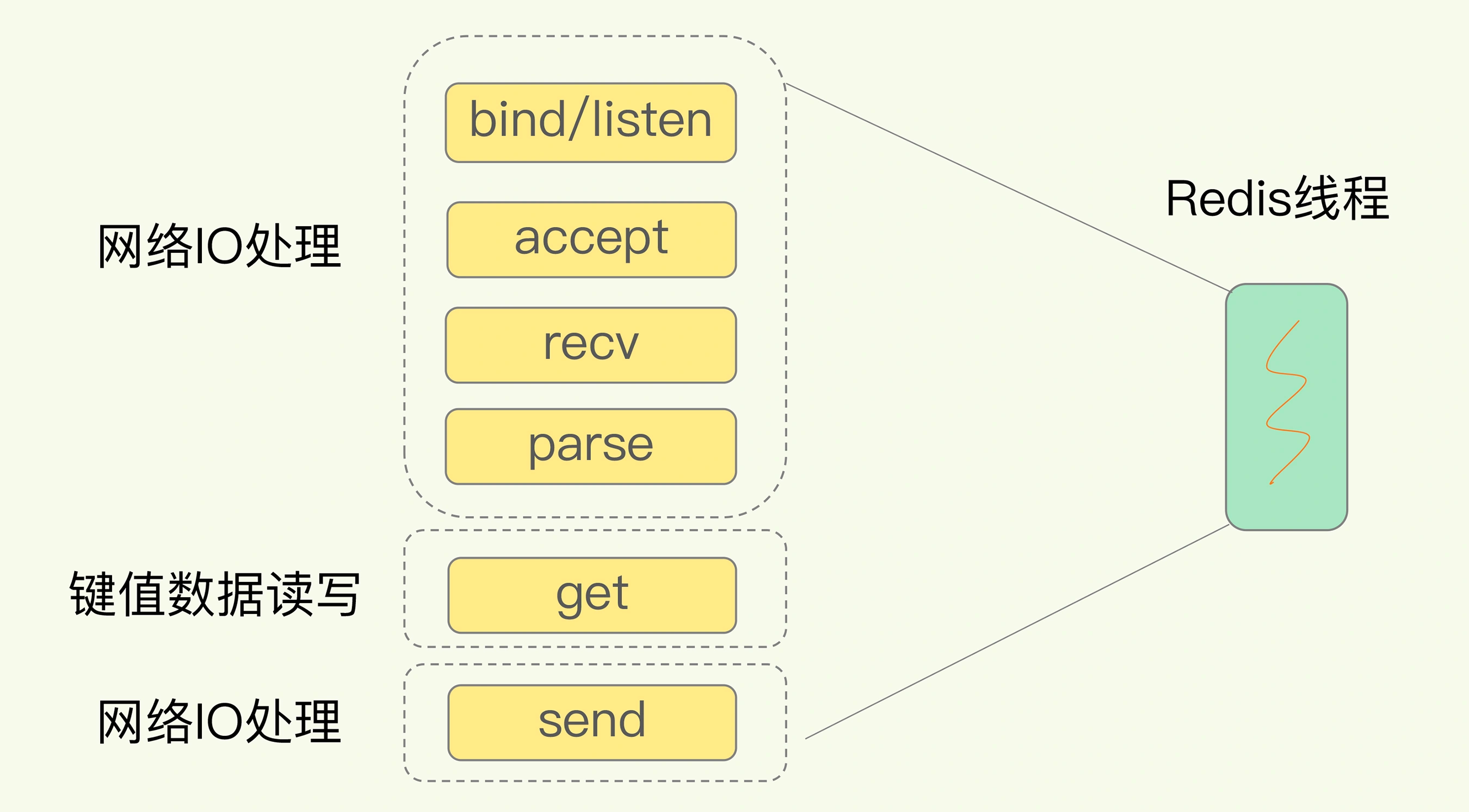
Optimize Kinds of Resource Use
1. 原则
1.1. 一言以蔽之
- 能批量就不要循环
- 能离线先算就不要在线算
- 能流计算就不要批计算
- 能让数据库算就不要内存算
- 比如同等数量下的JOIN操作
- 能利用数据库的任务就不要代码里面配任务
- 能N满足的就不要N+1
- 能保证并发没问题的就并发
- 能充分利用CPU等计算机资源的就不要过分利用
- 代码能先合并主干的就尽快合并
上述原则都埋了个坑,那就是什么怎么判断"能xxx"? 《数据密集型系统设计》这种书便充分总结了各种数据场景适用的技术。以下再根据个人经验做些论述。
1.2. 对原则的解释
1.2.1. Unix和数据库设计的不同思想
《数据密集型系统设计》认为,UNIX的目的是为程序员提供一个逻辑的,但是相当低层次的硬件抽象,而关系数据库则希望为应用程序员提供高层次的抽象(比高级程序语言更高)来隐藏数据结构的复杂性、并发控制、崩溃恢复等。因此,UNIX开发的管道和文件只是字节序列,而数据库开发了SQL和事务。书里进一步指出,NoSQL的发展可以解释为一种将低级别抽象的方法应用于分布式OLAP领域的诉求。关于这一点王垠也有过评论:
如果你看清了 SQL 的实质,就会发现这样的“过程式设计”并不会损失 SQL 的“描述”能力。有些人说你这样直接编程不好,因为外存的管理,索引数据结构,都是很容易出错的代码,还是不如用数据库。可是谁告诉你一定要自己写外存管理和索引代码呢?你完全可以使用经过千锤百炼的代码库,把它们放在服务器上面做成一个“存储索引系统”,你的“查询代码”只需要发送过去调用这些代码库就可以了。
1.2.2. 数据库可以当操作系统
私以为,大多数Web应用其实都是数据密集型系统,即围绕着数据的CRUD来实现业务逻辑。在这种情况下,越能直接让数据库代为计算的越能提高效率。而数据库本身也有着高度优化的执行引擎,对于大规模数据的持续计算也比直接运行应用程序更有优势。这种思想推导下去,便是让数据库成为像操作系统之于应用一样的存在--将应用程序代码直接部署在数据库中。
但也正如《数据密集型系统设计》"应用程序代码与状态分离"一节所指出的,数据库作为操作系统当今还不能满足应用开发的许多要求,比如版本控制、依赖管理、监控、追踪、测试、网络服务调用、系统集成等,并且Docker、k8s这些也都是专门为运行应用程序代码而设计的。所以对于并不是需要订阅变化,或者纯内部计算的应用场景,目前还是以在操作系统中部署应用代码为主。
比如下面谈到的流计算的缺点之一。
1.2.2.1. 流计算的缺点
流计算触发源本身和消息队列投递消息类似,不同的是流计算认为自己投递的是数据在时间维度上的变化,同时定义表为数据在某个时间下的快照。这也称之为流表二象性。流计算本质上也是在处理消息,不同的是实现业务逻辑的Java等程序语言会部分换成SQL,同时程序运行完全托管给Flink这种流计算框架而不用自己操心并发和机器资源的问题。
流本身处理时往往要依赖很多其他的数据,所以JOIN是很常见的操作。这通常要求缓存数据有边界的数据集进行查询,这个边界就是时间窗口。特别地,在双流JOIN中,对于小数据量可以使用REGULAR JOIN,即如果有一侧数据流增加一个新纪录,那么它将会把另一侧的所有的过去和将来的数据合并在一起。
因为缓存所以不可避免要碰到缓存带来的各种问题。
消息处理中遇到的幂等、消息乱序流计算也一样会遇到。幂等还好办,有主键就可以。
消息乱序则要考虑是消息源乱序还是处理时乱序,前者和后者都需要考虑对一定时间/数量窗口内的流排序或去重,后者不排序也可以选择冗余每个消息的顺序键自己做判断。
流上的数据源源不断的流入,就算引擎不可能等所有事件流入(也永远不会结束)再计算,也不会每次来一条事件就像操作传统数据库一样将所有相关事件捞出重新计算,因此在流式计算过程中,Flink选择增量计算的方式,每一次计算都会将计算结果存储到state中,下一条事件到来的时候利用上次计算的结果和当前的事件进行聚合计算。
分布式场景中,数据丢失、乱序、重复是常态,上述问题有些已经比较难处理,但是有个问题就在于流计算如Flink本身是自己定义了一堆SQL的,要准确地"拼接"SQL实现大段的逻辑是很让人痛苦的事情,尤其是在Flink这种作为计算运行框架,本身调试、错误处理机制是不完善的情况下。
当然我们可以用高级语言自定义函数去替代原有SQL,不过这终究失去了原本在应用中方便使用的集成测试、分布式追踪、日志搜索等功能。
1.2.3. 主干开发
传统的不停从master分支上来出来的个人开发分支的feature branch模式会导致代码没法持续push/merge,这样就没办法持续集成,会导致多分支切换问题,重构时也可能会导致大量的冲突。如果使用主干开发,就可以真正的小步快跑,持续集成发布。只是这有一定门槛,一方面这对于人员能力要求比较高,另一方面对需求管理的要求也比较高,需要做到需求可快速完成。实际执行中,不必关注是否是一个主干,重点是团队内成员开发代码和主干代码的集成频率。
据说Meta的移动端执行主干开发、分支发布,在主干fix bug,再cherrypick到发布分支;网站则使用主干开发,主干发布(1000人使用主干),每两小时自动发布一次,除非有人干预。
2. 工具
2.1. 线程池
- Java线程池实现原理及其在美团业务中的实践
- 线程数
- CPU密集型
- IO密集型
- 上下文切换成本
- 线程数
- hippo4j
3. 杂项
3.1. 开发查表
开发查询数据库始终有3种选择
一是大宽表,好处是可以充分利用离线计算,应用代码少,查的时候一般效率更高;坏处是笛卡尔积带来大量计算资源,存储资源消耗,表的构建时间也更长,同时宽表数据一致性不容易维护。
另一种是按照范式拆开各表,好处是结构清晰,单表不大;坏处是代码多,要反复和数据库连接查。
最后一种是也拆开表,但是统一用sql在数据库里面操作,避免网络开销,也充分利用数据库的缓存。
实践中可以适量冗余字段,并且尽可能利用数据库的计算能力
3.2. 业务逻辑放哪里
业务逻辑写在哪里呢?写在Converter中,写在Service层,写在DAO层,写在SQL里其实都可以,只能说开发人员要把握好各层的边界,尽可能写在Service中内聚业务逻辑。