



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
How-to-Choose-the-Suitable-Database
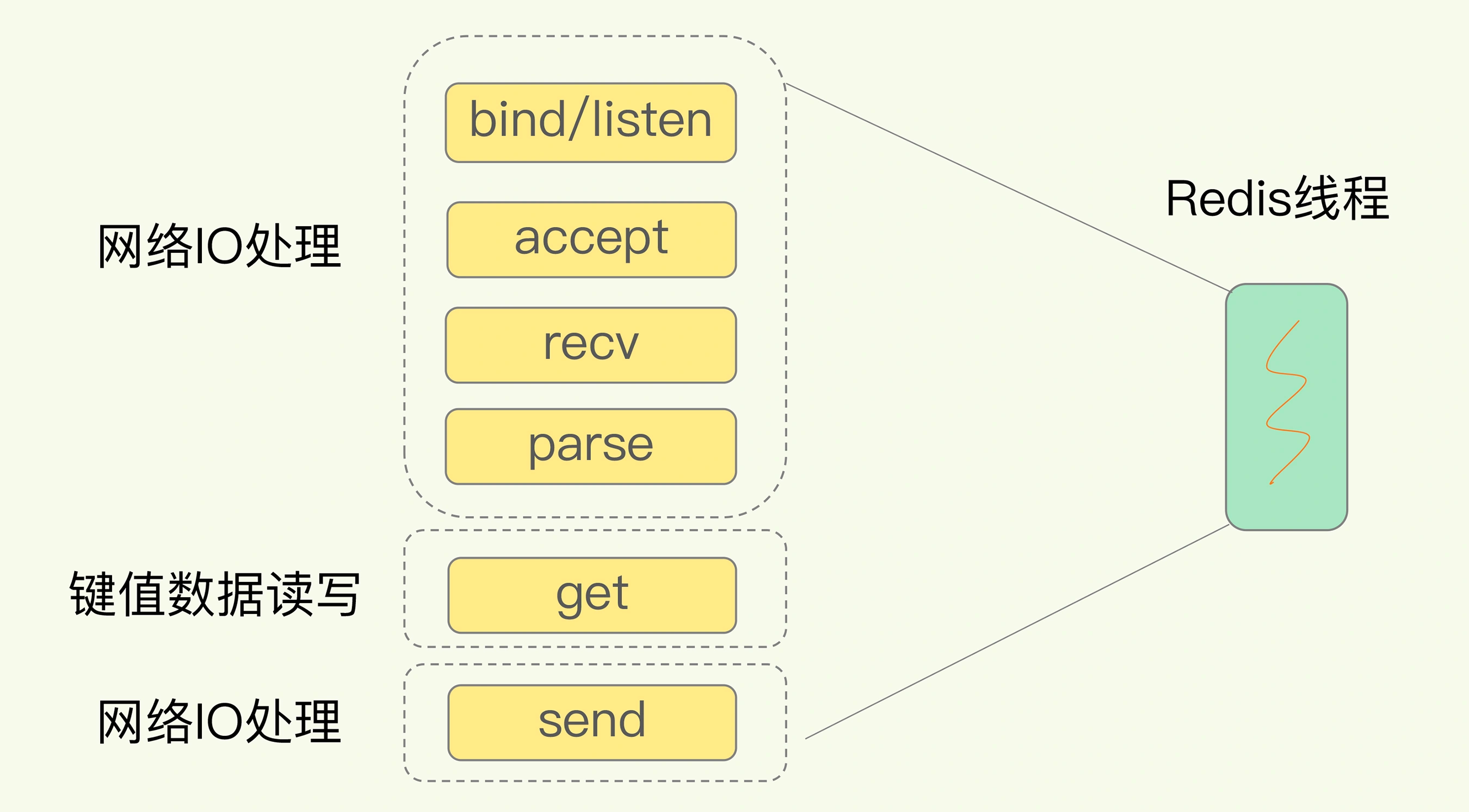
MySQL, to some extent, can be considered the "C language" of the database field. As a widely used relational database, MySQL is open-source, stable, and reliable, making it a preferred choice for many applications and websites. However, with the problems encountered in using relational databases like MySQL, a large number of NoSQL and NewSQL databases have emerged to address these issues.
NoSQL (Not Only SQL) is a category of non-relational distributed databases that aims to overcome the limitations of traditional relational databases in handling large-scale data processing and high concurrency scenarios. NoSQL databases emphasize scalability, high performance, and flexibility, making them suitable for applications that deal with massive and rapidly changing data patterns. Well-known NoSQL databases include MongoDB, Cassandra, and Redis.
NewSQL is an emerging database concept that combines traditional relational databases with Distributed Computing. It aims to provide the transactional consistency and data security of traditional relational databases, while also offering the scalability and high concurrency processing capabilities of distributed databases. NewSQL databases achieve data Horizontal Scaling and load balancing through innovative architectures and technologies such as sharding, replication, and intelligent routing. This combination of relational and distributed computing approaches satisfies the modern application's requirements for high performance, high availability, and strong consistency. Representative examples of NewSQL databases include Spanner, CockroachDB, and TiDB.
How do we choose a suitable database in face with kinds of databases?1

See more in https://dbdb.io/ and https://db-engines.com/en/ranking
The most important thing is definitely the business scenario in which our database is used. However, in this article, we will focus on the key differences between them, especially the main technology of them, because I believe none of a database can obtain all the advantages. When we encounter a new project, we should ask ourselves,
"How much innovation in basic technology does this project achieve, and what combination of existing technologies does it involve?"
Hardware & Technology
- New Hardware
- Data Create、Persistence & Backup
- Database System Self Implementation
- License
- Ecological Ecosystem
New Hardware
NVMe
NVMe, or Non-Volatile Memory Express, is a communication protocol designed specifically for high-speed solid-state drives (SSDs).
Compared to disk and memory, it strikes a balance between cost and random access performance.
RDMA
Data Create、Persistence & Backup
Data Model
Data Model defines how data is stored, arranged, and accessed in a database system. 2
- Relational – with data organized in tables related to each other, like MySQL and PostgreSQL;
- Hierarchical – a tree-like structure, organizing data into parent-child relationships;
- Network – based on the hierarchical model, with the possibility of many-to-many parent-child relationships;
- Object-oriented – store data as objects, for example, JSON documents or media files; meant to conform to the needs of object-oriented programming and multimedia-based software, like MongoDB and Simple Storage Service. Although S3 stores data as objects in a flat address space.
- Object-relational – also called hybrid, as it is a mixture of relational and object-oriented approach to database modeling;
- Entity-relationship – data is stored in a way to reflect relationships between entities, their attributes, or processes.
- Inverted index – a data store that organizes a list of identifiers (indexes) of certain data elements within a file, document, or a set of documents – most often applied in full-text search such as we do with search engines, like ElasticSearch;
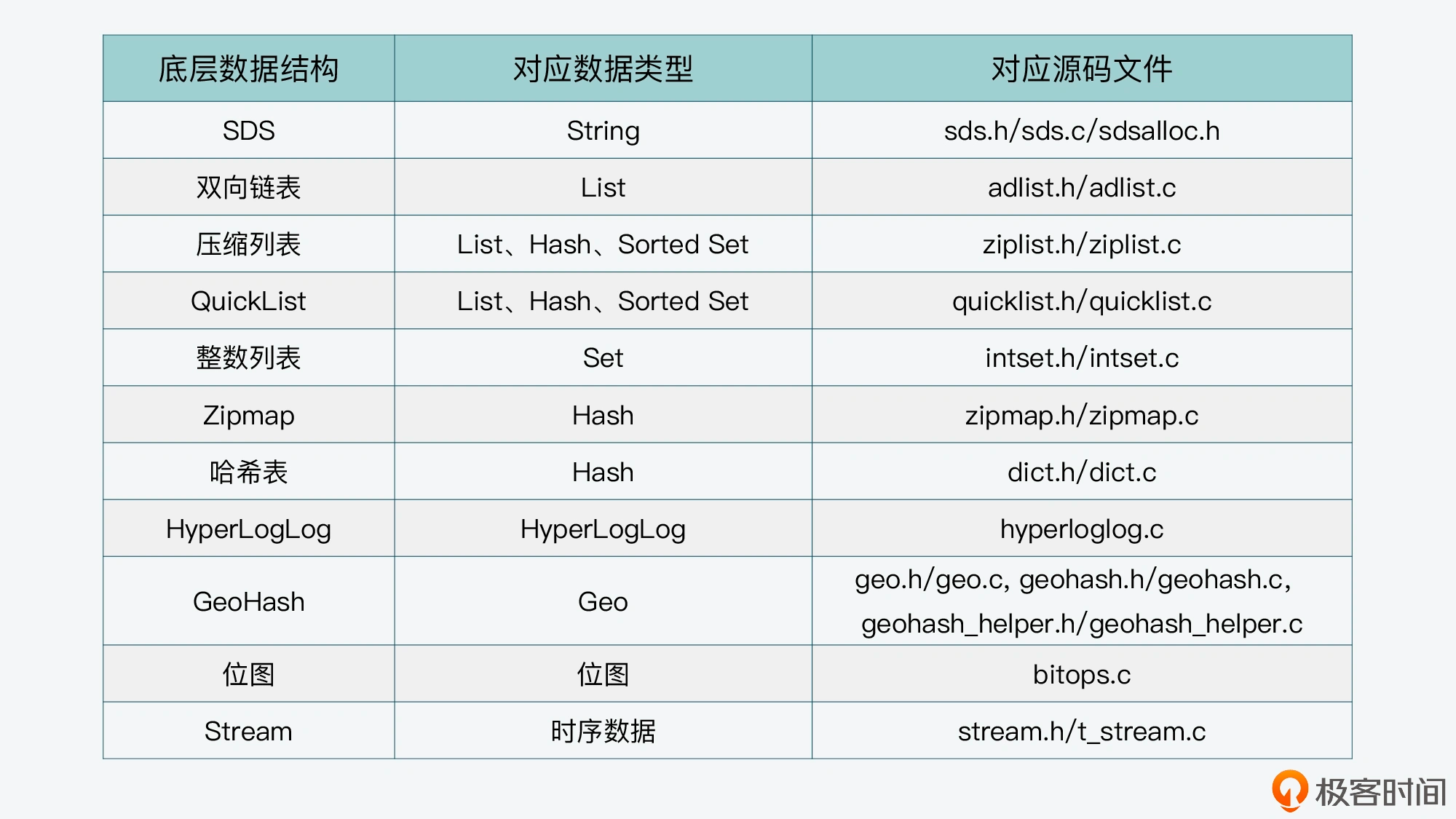
- Multidimensional – a complex cube-like data structure based on a variation of relational database which is used for data analytics and viewing the same data from different perspectives. Redis is an in-memory key-value store, supporting various data structures like strings, lists, sets, and hashes.
Index Structure
- ...traditional data structure like list、array
- Redis uses in-memory data structures for indexing, providing fast access to data.
- bitmap
- dictionary encoding
- B+ Tree , which is a multiway unbalanced binary tree existing on disk.
- PostgreSQL uses B+ Tree as its primary index structure, along with other index types like hash, GiST, and SP-GiST.
- MongoDB uses B-Tree indexes, which are similar to B+ Tree but with some differences in node structure and traversal.
- ElasticSearch uses an inverted index for full-text search and analytics.
- Percolator model
- TiDB uses a distributed index structure based on Google's Percolator model
- HNSW:Vector-Database
Data Persistence Format
If a computer wants to write data from memory to disk, it typically needs to perform at least two steps:
Column
Examples: Optimized-Row-Columnar
Column storage is suitable for OLAP(Online Analytical Processing) scenarios:
- data scanning
- filtering
- statistical analysis
Row
Row storage is suitable for OLTP(Online Transaction Processing) scenarios:
- Primary Key select
- ACID
Examples:
Coexistence of Rows and Columns
In a traditional column storage database, data is stored by column rather than by row. This can be beneficial for analytical queries that aggregate values in a column because the database can read the column data in a continuous disk scan.
Examples:
LSM
Examples: Inverted Index
Backup Strategy
Write-Ahead Logging
AOF(Append Only File)
Redis doesn't use a traditional WAL, but its AOF persistence mode has similarities with the concept of Write-Ahead Logging. The AOF and Write-Ahead Logging share the principle of logging changes to data before they are applied, providing a way to recover the state of the data in case of a crash.
AOF persistence logs every write operation received by the server. These operations can then be replayed again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself.3
AOF can be configured to sync to disk at different frequencies based on the fsync policy. This allows you to balance between write performance and data durability.
RDB(Redis Database)
RDB persistence performs point-in-time snapshots of your dataset at specified intervals.3
RDB + AOF
-
AOF rewrite: The AOF gets bigger and bigger as write operations are performed. While AOF file size exceeds the limit, Redis continues appending to the old file, a completely new one is produced with the minimal set of operations needed to create the current data set, and once this second file is ready Redis switches the two and starts appending to the new one.
-
Mixed RDB with AOF rewrite: When AOF is performing a AOF rewrite, Redis first writes a data snapshot in RDB format to the AOF file, and then appends each write command generated during this period to the AOF file.
Database System Self Implementation
Connection Model
Spawning a New Process on Each Connection
The process model provides better isolation, for example, an invalid memory access error can only crash a single process, rather than the entire database server. The process model, on the other hand, consumes more resources like memory.
Example
- PostgreSQL
Spawns a New Thread on Each Connection
- MySQL
Concurrency Control
- MySQL and PostgreSQL use multi-version concurrency control (MVCC) to handle concurrent transactions.
- Redis uses single-threaded execution, processing one command at a time.
- Elasticsearch, MongoDB, and TiDB support optimistic concurrency control.
- ClickHouse uses a lock-free data structure for concurrent query execution.
Database Solutions for Distributed Systems
Theoretically, distributed databases have higher availability due to the avoidance of single points of failure. However, in practice, there are currently some drawbacks to distributed databases, such as:
1. Incomplete functionality: They only support simple CRUD operations and do not support complex SQL syntax and analytical functions. The quality of distributed execution plans is not high.
2. Unstable performance: Due to the need for multiple network communications and distributed coordination, there is a significant performance loss compared to single-machine databases.
3. High complexity: Distributed databases involve multiple components and nodes, making operations and management difficult, and troubleshooting is challenging.
4. Low reliability: Distributed databases, due to the introduction of more failure points, are prone to issues such as data loss, inconsistency, and split-brain problems.
License
- MySQL Community Edition is licensed under the GPL.
- Postgres is released under the PostgreSQL license, a free and open source license similar to BSD or MIT.
Ecological Ecosystem
Evaluation & Use
Evaluation Standards of Common Database
- Cost
- Performance
- Query Optimizer
- Data Consistency
- Usability
- CTE (Common Table Expression)
- Advanced Function or User Defined Function Support
- Operability
- Extensibility
- Security
Cost
Performance
Query Optimizer
Data Consistency
- MySQL, PostgreSQL, and TiDB provide strong consistency through ACID transactions.
- Redis offers tunable consistency levels, depending on the configuration.
- Elasticsearch and MongoDB provide eventual consistency.
- ClickHouse focuses on read consistency for analytical queries.
- OSS and Simple Storage Service provide eventual consistency for object storage.
Usability
Support for Global Indexes
Local indexes are friendly to transaction performance and are all local transactions. However, they have the disadvantage of read amplification.
Global indexes avoid read amplification, but they convert all transactions into distributed transactions, greatly increasing transaction complexity and slowing down the performance of individual transactions.
Query Language
- MySQL and PostgreSQL use
SQLas their query language. - Redis has its own
set of commandsfor data manipulation. - Elasticsearch uses a JSON-based query language called
Query DSL. - MongoDB uses a
JSON-like query language. - TiDB supports
SQLand is compatible with the MySQL protocol. - ClickHouse uses
SQLwith extensions for analytical functions.
JSON Support
Both Postgres and MySQL supports JSON column. Postgres supports more features, like allowing indexes to be created on JSON fields.
CTE (Common Table Expression)
Postgres has more comprehensive support for CTE:
- SELECT, UPDATE, INSERT, DELETE operations within the CTE
- SELECT, UPDATE, INSERT, DELETE operations after CTE
Advanced Function or User Defined Function Support
Operability
Extensibility
Postgres supports several extensions. The most outstanding is PostGIS, which brings geospatial capabilities to Postgres. In addition, there is Foreign Data Wrapper (FDW), which supports querying other data systems, pg_stat_statements for tracking planning and execution statistics, and pgvector for vector searches for AI applications.4
Security
Use Cases
- MySQL and PostgreSQL are suitable for traditional transactional applications, such as web applications and e-commerce platforms.
- Redis is ideal for caching, session management, and real-time analytics.
- Elasticsearch is best for search and log analytics use cases.
- MongoDB is suitable for large-scale, schema-less applications, such as content management systems and IoT platforms.
- TiDB is suitable for hybrid transactional and analytical processing (HTAP) workloads.
- ClickHouse is ideal for real-time analytics and reporting.
- OSS and Simple Storage Service are suitable for storing large amounts of unstructured data, such as images, videos, and backups.
Other Cases
- 一名开发者眼中的 TiDB 与 MySQL 的选择丨TiDB Community
- 数据库选型:MySQL、PolarDB、PolarDB-X、TableStore、MongoDB、TiDB、ClickHouse:
References
:4 全方位对比 Postgres 和 MySQL (2023 版)
Appendix
- GPT4 Prompt
As an expert on databases, your task is to provide a summary of ten dimensions that illustrate the differences between databases such as MySQL, PostgreSQL, Redis, ElasticSearch, MongoDB, TiDB, ClickHouse, OSS, Simple Storage Service, and others. The dimensions should include factors such as data model, infrastructure, index structure, data-sync strategy, data store strategy and other technical factors. Your summary should explain the reasons why these differences exist and how they affect the suitability of each database for different use cases.
Your response should be clear and concise, highlighting the most significant differences between each database and the advantages and disadvantages of each in relation to the ten dimensions mentioned above. Your response should be flexible enough to allow for various relevant and creative reasons for the differences between databases. For example, you could explain that MySQL uses a B+ Tree data structure, which is effective for storing large amounts of data on disk, while MongoDB uses a document-based data model that is more flexible but can be less efficient for certain types of queries. For example, you at least tell people that MySQL uses B+ Tree as the major index which is a Multiway Unbalanced Binary Tree existing in the disk, and it usually uses sub-library and sub-table strategy when it stores over 2000 thousand records.
Your goal is to provide a comprehensive and informative overview of the major technical differences between these databases and the reasons why these differences exist, while also encouraging creative and relevant explanations to make the summary unique and engaging.