



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
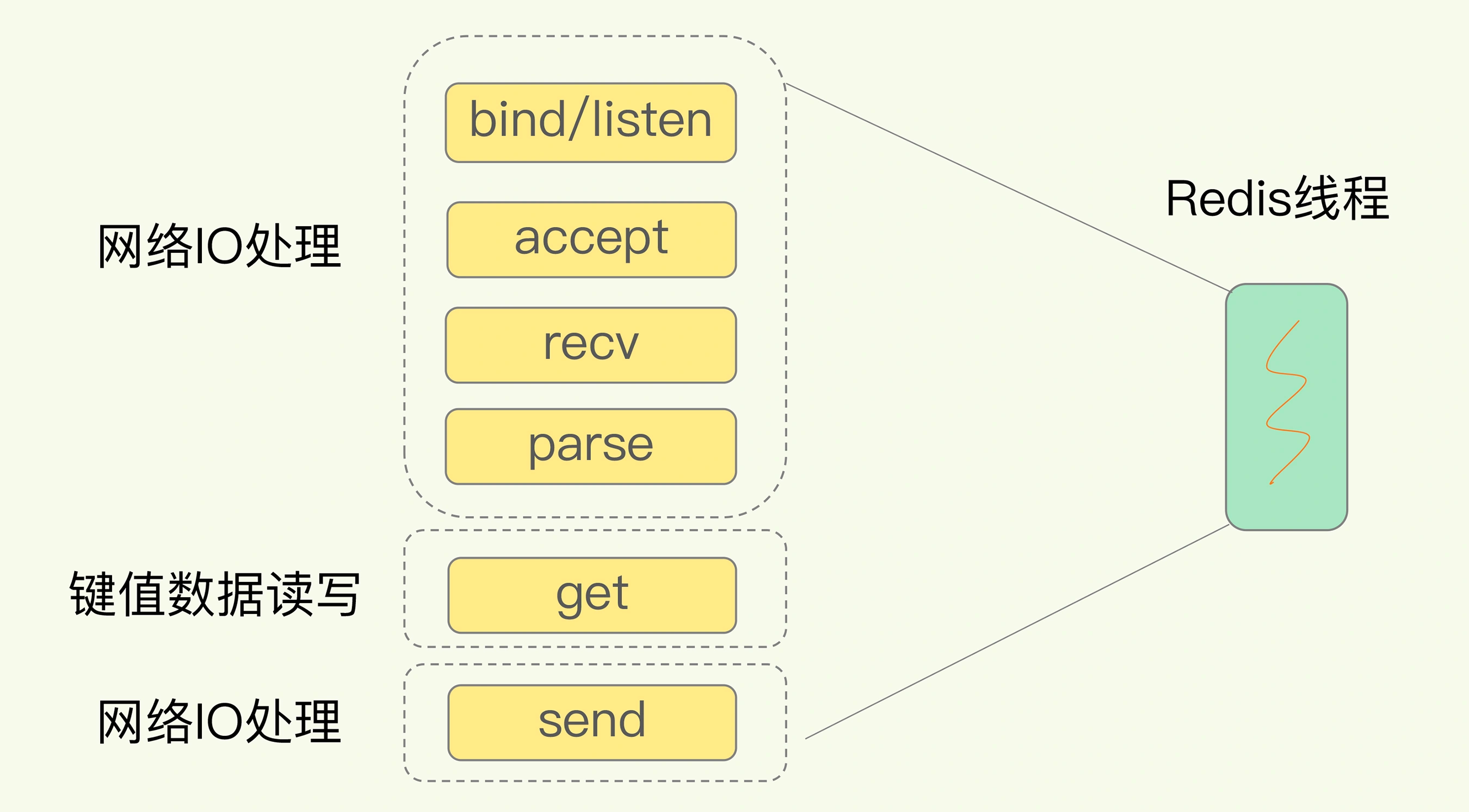
Hologres
Data Storage Partition2
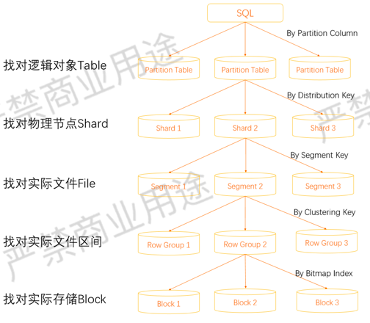
如上所示,用户写了一个SQL之后,首先会按照用户分区键路由到对应要找的表上面,找对逻辑对象Table。
第二步通过distribution_key找到对应Shard。
第三步是 segment_key,找到Shard之后要找对应Shard上面的文件,因为实际数据是存储成一个个文件,我们通过segment_key找到想要打开的文件。
第四步是在文件内部,数据是否有序,这是通过clustering_key来查找的,Clustering Key帮助我们找对实际文件区间。
第五步是Bitmap。因为Hologres把数据按照一个个Batch存储,在一个Batch里面,我们需要通过Bitmap快速定位到某一行,否则需要把某一个区间范围内所有的数据扫一遍。
图中从上往下不同的过程,越来越到文件内部,越往上是越大的范围。
distribution_key 分布列
Hologres在存储的时候,是把物理表分成一个个Shard存储,每个表会按照一定的分布方式分布到所有的物理节点上面,然后每个Shard可以去并发进行查询,Shard数越多,相当于整个查询的并发度越高。
如果创建了Primary Key索引(用于数据更新),默认为distribution_key, Distribution_key如果为空,默认是Random,Distribution_key需是Primary Key的子集。Hologres 使用Distribution_key均衡地分发数据到多个Shard中,令查询负载更均衡,查询时直接定位到对应Shard。
假设两个表做关联,如果都按照关联的Key去设计Distribution Key,那么这两个表的关联就可以做一个Local Join。
分区Key
分区表:也是物理表,具备一样的Shard能力,但多了一个根据分区键进行Table Pruning的能力。通常情况下,分区的Key是静态的,并且数量不会太多,最适合做分区Key的是日期。
segment_key 分段列
和分区Key类似。Segment_key用于文件块的边界划分,查询时基于Segment_key可以快速定位数据所在文件块, Segment_key多列时,按照左对齐。在列存上面,文件是存成一个个Segment,当查询到了某一个Shard上,因为Shard内部有一堆的文件,我们要去找哪些文件会命中这个查询,需要进行扫描,Segment Key是用来跳过不需要查找的文件。
clustering_key 聚簇列
Clustering_key用于文件内聚簇布局,表示排序信息,和MySQL 的聚簇索引不同,Hologres用来布局数据,不是布局索引,因此修改Clustering需要重新数据导入,且只有一个 Clustering_key,排序操作在内存中完成生成SST(Sorted String Table)。
ClusteringKey的设计是按照最左匹配的原则,就是当遇到用户的查询条件,也按照最左匹配的原则来匹配。
Bitmap 位图索引

位图索引,对于等值过滤场景有明显的优化效果,多个等值过滤条件,通过向量比较计算。位图索引主要的应用场景是在点查过滤。
同样的,位图索引也有个问题,就是基数过多的列,在位图索引编码时,会形成稀疏数组(列很多,值很少),对查询性能改善影响小。
Difference between PostgreSQL and Hologres
之所以这样问,是因为Hologres 兼容大部分 PostgreSQL 的语法,以及报错堆栈也与之相像。实际上Hologres这个词是holographic和Postgres的组合,Postgres指的是兼容PostgreSQL生态,holographic指的是全部信息,代表官方希望Hologres对数据进行全息的分析(HSAP ),并且能够兼容PostgreSQL生态1。
Hologres 相比PostgreSQL 主要做了以下创新:
- 在tablet层面同时支持了row tablet 和 column tablet,并且是双份而不是raft同步
- 所有查询都在内存中完成,哪怕OOM(?)
- 引入了bitmap、dictionary encoding 提高查询速度,不过 PostgreSQL 有插件,更多索引都能支持
- Hologres 采用了 存算分离的架构
hologres 存算分离有一个很重要的特征,它将计算单元放到了 docker 中。