



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Possible Problems with Sharding and Partitioning
当单表数据量过大时,其读写性能都会受到严重影响。一般来说,单行记录2KB以上,或者数据记录2000万行 以上&&十亿行以下可以考虑分表;数据库表较多,单库并发量较大的,并且表对应的业务逻辑较为高内聚、低耦合的,可以考虑分库。
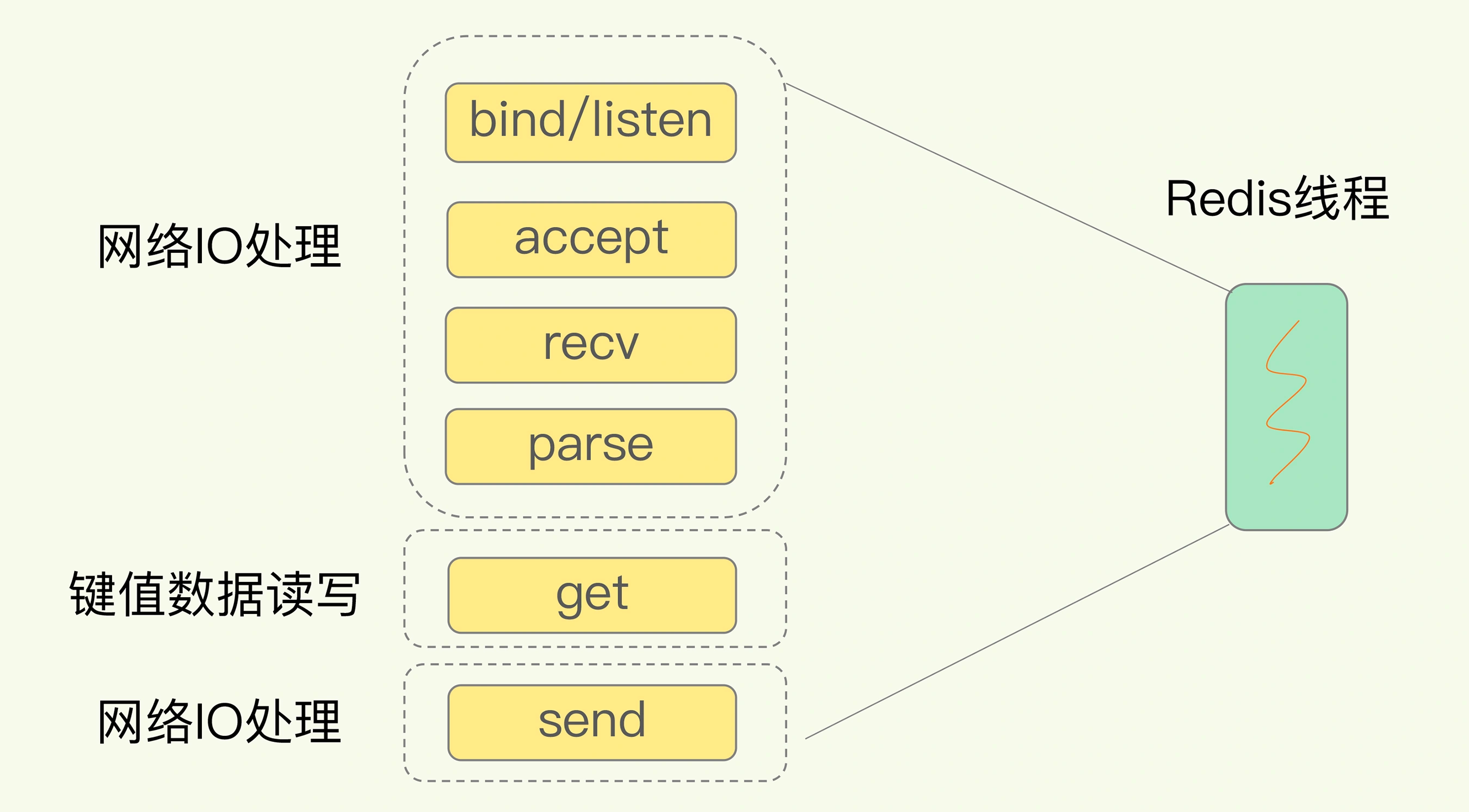
JDBC 代理模式
Java 中分库分表有偏应用还是偏 DB两种,即JDBC 代理模式与Sharding On MySQL 的 DB 模式 。
JDBC 代理模式其实可以理解为一个增强版的JDBC驱动,比如阿里的TDDL.TDDL可以仅为一个Jar包在项目中引入后配置好分库分表规则,每次在调用的时候,TDDL自动替换好SQL,再调用实际的JDBC和SQL即可完成操作,如下图所示:
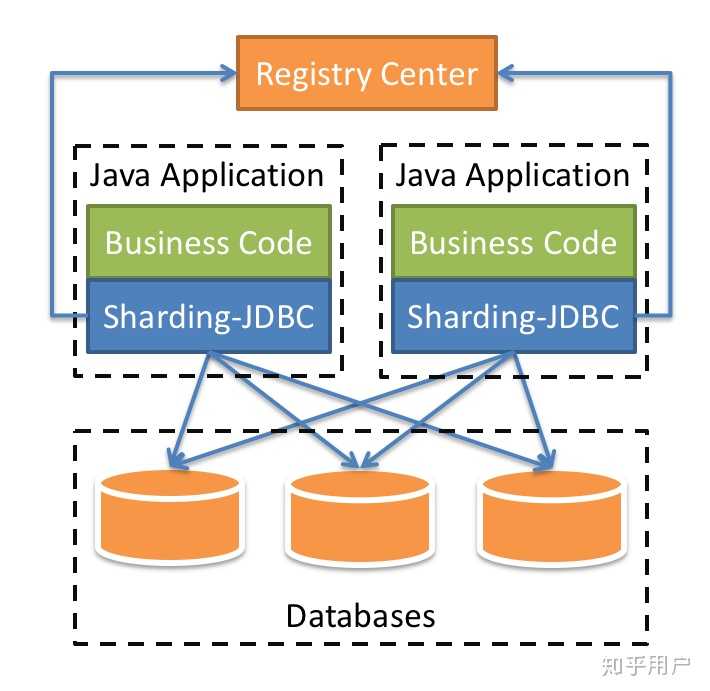
JDBC 代理模式或者说这种应用层代理模式因为要糅合分区逻辑在代码里面,问题是比较多的。
糅合分区逻辑在代码中的问题
1. 频繁变动拆分规则
通常来说,分库分表键是业务最常用的等值查询条件,其次需要考虑分表后数据分布的均匀度.
因为业务的变化,大数据量的分表容易变动拆分规则,每次规则变动都可能涉及到数据的重新搬迁,并且业务端还需要投入大量的人力去维护路由规则。
路由规则
ID取模
- 优点:新写入数据可以均匀写到多张表
- 缺点:不利于新增分表。比如一开始分了5张表,模是5,如果改为10张表,模是10,原有数据路由规则就变动了需要迁移数据。
ID范围分表
- 优点:表可以依数据量增多
- 缺点:容易出现“写热点“。因为新写入数据这种情况下会落到一张表上,大量写入数据就会反复写一张表。
ID某个范围内取模
比如0~1亿中间分5张表。综上优缺点。
2. 主键不严格递增
数据源总是需要一个唯一的主键标志数据库记录,在单库单表的情况下,数据库设置一个唯一自增的主键即可;但是在多库多表的情况下,还需要各个表生成的主键是多库多表下唯一的。通常TDDL会设计一个Sequence表记录全局可用的ID,然后让需要生成记录的节点取回与之前不相同的ID并缓存在应用中以待新增记录时分配ID。当应用用完这批或者重启时会重新向sequence获取ID序列,而每个节点申请到的ID各不相同,这样就保证了全局有唯一主键。
但是从以上TDDL生成主键原理也可以看出来,因为是各自节点自己分配,对于新增的记录主键不一定是严格递增的。
3. 分布式事务
当更新内容同时分布在不同库中,不可避免会带来跨库事务问题。可以使用如“两阶段提交” 的方法来解决这个问题。
3.1. 两阶段提交
- 阶段一:全局的事务管理器向各个数据库发出准备消息。各个数据库需要锁住资源,记录redo/undo日志,但是并不提交,从而进入一种时刻准备提交或回滚的状态,然后向全局的事务管理器报告准备好了;
- 阶段二:当所有的数据库都报告说准备好了,那么全局事务管理器就统一指挥各个数据库提交操作。
如果有任何一个数据库报告没准备好,全局事务管理器就统一指挥各个数据库回滚,并且释放在阶段一锁住的各种资源。
两阶段提交的典型实现有Java Transaction API(JTA)。两阶段提交虽然保证了多个数据库操作结果的强一致性,但是因为提交分布式事务时需要协调多个节点,性能差,延长了事务的执行时间;还导致其在访问共享资源时发生冲突或死锁的概率增高。
所以人们退而求其次只追求最终一致性,比如Dan Pritchet提出的BASE理论:
3.2. BASE模型
BA(Basically available):基本可用性,基于CAP理论,在系统各数据强一致性与系统可用性之间的一种状态。S(Soft state):可以理解为没有达到最终一致性的短暂状态E(Eventually consistent):事务情况下期望的系统终态
可以基于消息传递实践BASE理论,以A向B转账100元为例:
- 扣除A账户100元
- 向与A账户同处于一个数据库的事件表T中插入信息I--"A向B转账100元",这里使用本地事务即可
- 向A返回转账成功,此时系统处于基本可用状态
- 定时任务捞取T中事件写入消息队列M
- B从M中消费I(B中消费应幂等,以防重复被发消息)
- 此时系统达到最终一致性
4. 读扩散:查询没有分库分表键拖慢查询
TDDL实际会对SQL进行转换来操作单个库和表,有了分库键才能允许TDDL定位SQL具体的执行库表完成SQL对应库名表名的替换。
对于单纯的select,
- 如果没有分库分表键的话需要全库全表扫描,并且有多少张表就要执行多少次sql--这也被称作
读扩散问题。 - 对于分页、Max、Min、Sum、Count这种操作,则还需要在各个分片(Atom)上进行对应的操作,最后将结果汇总到一起(Matrix)再进行计算才能返回结果。
可以对分库分表键及其他查询条件单独建表索引以备加速查询,或者直接引入倒排索引更方便。
5. JOIN操作很慢或者不支持
5.1. 问题描述
切分之前,系统中很多列表和详情页所需的数据可以通过sql join来完成。而切分之后,开发面临的只是TDDL暴露的一张逻辑库,有以下考虑不会支持JOIN:
1. 跨库join性能上难以接受
2. join写的sql语句在修改表的schema时,不容易发现并维护
3. DB可能本身承担业务压力已过大,最好内存中处理
那么原本要通过JOIN获得的能唯一确定需要的记录的字段,就需要先行查出再作为条件去二次查询了。举个例子,取xxx_no单据号上最新的目标column字段,也就是要选出gmt_modified最大时的column字段
5.2. 如何解决
SELECT xxx_no, gmt_modified
FROM xxx
where supplier_id_lv1= '123451234512345'
and sc_item_id= '678967896789'
ORDER BY gmt_modified desc
limit 1
但是我们其实不需要 gmt_modified,返回两个字段在批量查询时将不可避免反复ORM开销。为此,可以使用子查询直接查出 xxx_no :
select xxx_no
from(
SELECT xxx_no, gmt_modified
FROM xxx_order
where supplier_id_lv1= '123451234512345'
and sc_item_id= '678967896789'
ORDER BY gmt_modified desc
limit 1) AS tmp
只是分库分表的逻辑表不支持子表查询。
5.3. 其他解决办法
如果不是逻辑表,我们也可以这样写,注意我们这里需要的只是column:
select xxx_no,column,gmt_modified from xxx as a
JOIN
(
select xxx_no,max(gmt_modified)
from xxx
where fenkujian = ? and xxx_no = ?
group by xxx_no
) as b
on a.xxx_no = b.xxx_no and a.gmt_modified = b.gmt_modified
现在需要拆成两步:
select xxx_no,max(gmt_modified) as max_gmt_modified from xxx where fenkujian = ? and xxx_no = ? group by xxx_no;
2.(批量的要使用or连接或者union)
select xxx_no,column from xxx where fenkujian = ? and xxx_no = ? and gmt_modified = max_gmt_modified;
当然如果不是批量操作(比如sql in xxx_no),又希望一步到位的,因为gmt_modified一般18位数(yy--mm-dd hh:mm:ss),可以把上述操作改成一步:
select SUBSTR(MAX(CONCAT(LPAD(`gmt_modified`,18,'0'),column)),7) as column ...
5.4. 错误的写法
- 如果这样写:
select xxx_no,column,max(gmt_modified)
from xxx
where fenkujian = ? and xxx_no = ?
group by xxx_no
语法上不一定会报错,但是取出来的column其实与gmt_modified没有任何对应关系。
- 如果这样写:
select xxx_no,column,gmt_modified
from xxx
where fenkujian = ? and xxx_no = ?
group by xxx_no
having gmt_modified = max(gmt_modified)
会报错:Unknown column 'gmt_modified' in 'field list',应该是having中使用的窗口函数需要在select list中出现。
而如果这样写:
select xxx_no,column,max(gmt_modified) as gmt_modified
from xxx
where fenkujian = ? and xxx_no = ?
group by xxx_no
having gmt_modified = max(gmt_modified)
那其实就等于
select xxx_no,column,max(gmt_modified) as gmt_modified
from xxx
where fenkujian = ? and xxx_no = ?
group by xxx_no
having 1 = 1
DB 代理模式
后来业界重点发展DB的代理模式,并且越来越底层。

这些方案与产品实现者在生态兼容性与业务改造上越做越好。

DB代理模式允许用户不再感知分区逻辑,由DB或DB的中间件直接决定如何分区、路由,以及适配集群节点的增加与删除。这种有两种实现方式:
| 分区键 | 路由规则 | 评价 | 使用场景 |
|---|---|---|---|
| 均匀分布的key | 基于key 的路由规则 | 不带key还是不方便读写 | Redis Cluster |
| 全局唯一键 | 基于全局唯一键的路由规则 | 事务都变成分布式事务 | - |